Computer Science
A* Search : 8-퍼즐 문제로 알아보기
2025-09-16
8-퍼즐이 뭐에요?
8-퍼즐이란 3x3 격자판에서 1부터 8까지 숫자가 쓰여있는 8개의 타일과 하나의 빈칸을 움직여 타일을 순서대로 배열하는 퍼즐입니다. 저 역시도 어릴적 만화 캐릭터가 그려진 8-퍼즐을 풀곤 했는데, 잘 안될 때마다 어머님께 부탁드렸던 기억이 납니다. 한동안 잊고 살다가 26살이 되고 나서야 이 퍼즐을 해결할 방법을 알아냈습니다. (처음 들어보신다면 아래 퍼즐을 움직여 문제를 한 번 풀어보세요)
문제 해결은 곧 탐색
퍼즐은 초기 상태로 시작합니다. 초기 상태에서 할 수 있는 행동은 다음과 같습니다.
1. UP: 빈칸을 위로 올리기 (타일을 아래로 내리기)
2. DOWN: 빈칸을 아래로 내리기 (타일을 위로 올리기)
3. LEFT: 빈칸을 왼쪽으로 옮기기 (타일을 오른쪽으로 옮기기)
4. RIGHT: 빈칸을 오른쪽으로 옮기기 (타일을 왼쪽으로 옮기기)
타일의 상태에 따라서 특정 행동은 불가능할 수도 있습니다. 이미 빈칸이 가장 위에 있는 경우, UP 동작은 불가합니다.
각 행동을 할 때마다 퍼즐의 상태는 변화합니다. 우리의 목표는 위 행동들을 조합하여 가장 적은 횟수만으로 목표 상태(1부터 8번 타일이 정렬된 상태)에 도달하는 것입니다.
목표 상태에 도달하기 위해 퍼즐은 여러 상태를 거쳐야 합니다. 이 상태들의 전이를 그림으로 표현해보면 다음과 같을 것입니다.
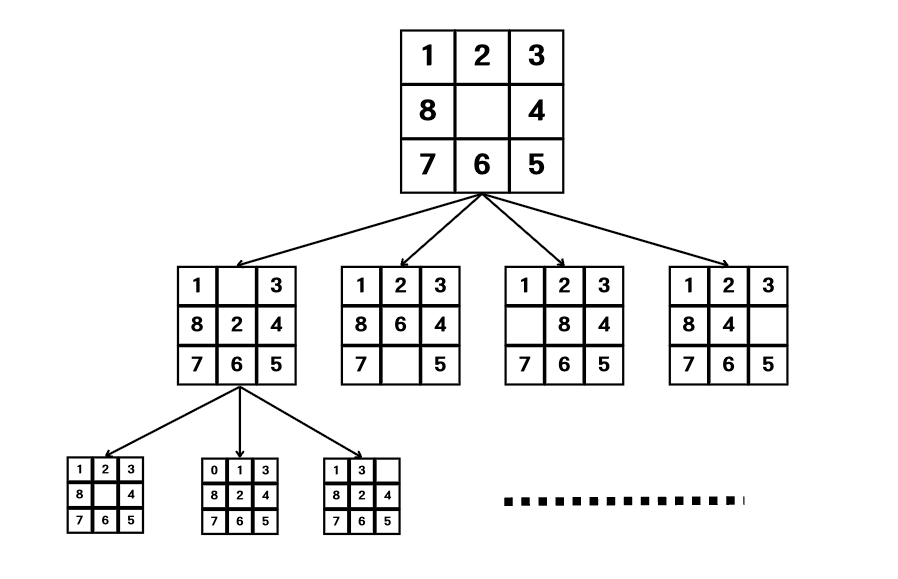
각 상태들은 다음 상태들을 낳고, 이는 트리 구조를 보입니다. 트리들을 탐색하다보면 언젠가는 목표 상태에 해당하는 타일이 나올 것이며, 트리의 깊이는 이동 횟수를 나타내므로 BFS를 사용하면 최소 움직임으로 목표 상태로 이동하는 방법을 찾을 수 있습니다.
BFS을 통한 해결
중복 처리
BFS로 구현을 할 때에는 중복 처리를 신경써주어야 합니다. 가장 먼저 만날 수 있는 중복은 첫 행동의 반대 행동이 바로 이루어지는 상황입니다. UP -> DOWN 행동이 이루어지면 원래의 상태로 돌아갑니다. 반대 행동만 막는 것은 완벽하게 중복을 막을 수 없는데, 이는 UP -> LEFT -> DOWN -> RIGHT와 같은 사이클이 발생할 수 있기 때문입니다.
이를 간단하게 해결하기 위해 배열인 각 퍼즐 상태를 문자열로 직렬화하고, 상태 문자열을 집합에 저장하여 중복된 상태가 발생하지 않도록 만들어주었습니다.
구현
public static class Node {
final int[][] board;
final int moved;
// constructor
}각 노드는 3x3의 퍼즐 상태와 기존에 몇 회 움직였는지에 대한 정보를 가지고 있습니다. (기타 최적화에 필요한 변수들은 다 숨기고 핵심 필드만 남겼습니다.)
void solve() {
Node initial = new Node(new int[][]{
{8, 6, 7},
{2, 5, 4},
{3, 0, 1}
}, 0);
Queue<Node> q = new LinkedList<>();
Set<String> visited = new HashSet<>();
int nodeVisits = 0;
visited.add(serialize(initial.board));
q.add(initial);
while (!q.isEmpty()) {
Node node = q.poll();
nodeVisits++;
if (isGoal(node.board)) {
System.out.println("Total nodes visited: " + nodeVisits);
System.out.println("Solved in " + node.moved + " moves.");
return;
}
List<Node> nextNodes = expand(node);
for (Node n : nextNodes) {
String serialized = serialize(n.board);
if (!visited.contains(serialized)) {
visited.add(serialized);
q.add(n);
}
}
}
}초기 상태 노드로 시작하여 순회를 시작합니다. 노드 방문 이후 expand() 함수를 통해 각각의 액션이 수행된 이후 상태의 노드들을 생성하며, 해당 상태가 중복이 아닌 경우 큐에 추가됩니다.
이를 통해 31번의 이동으로 주어진 초기 상태의 퍼즐을 목표 상태로 만들 수 있다는 것을 알게 되었습니다. 이 과정에서 방문한 노드 수 역시 계산하여 출력해 보았고, 결과로는 181,439회가 나왔습니다.
닥터 스트레인지는 시간 조종 능력이 있어 무수한 경우의 수를 보고 나서도 원래 시간으로 돌아올 수 있습니다. 하지만 컴퓨터는 그런 능력이 없어 경우의 수를 보는데에 시간이 소비됩니다. 지금은 3x3 퍼즐이라 금방 되지만, 4x4, 5x5와 같이 늘어난다면 수행 시간은 기하급수적으로 늘어날 것입니다.
A* Search를 통한 해결
Traditional Search vs Informed Search
BFS는 전통적인 탐색 방식으로써, 어떤 입력이 들어오든 항상 기계적인 규칙을 토대로 노드를 탐색합니다.
한 편, 휴리스틱 탐색Informed Search 방식은 문제에서 주어진 정보를 바탕으로 탐색을 진행합니다. 이를 통해 전통적 탐색 방식보다 더 효율적으로 솔루션을 찾을 수도 있습니다.
Best-first Search는 휴리스틱 탐색의 한 예로, 평가 함수 f(n)을 토대로 각각의 상태 공간이 얼마나 목표에 근접할 가능성이 있는지를 추정합니다. 이를 토대로 가장 목표에 근접하다고 예측되는 트리를 우선적으로 탐색하여 불필요한 탐색을 줄일 수 있습니다.
A* Algorithm (A* Search)
A* Algorithm 혹은 A* Search라고 불리는 알고리즘은 Best-first Search 방식을 사용합니다. 평가함수를 통해 상태들의 가능성을 예측하고, 불필요한 가지는 잘라버림으로써 더 적은 노드를 탐색하고 효율적으로 결과를 도출해냅니다.
A* Search의 평가함수 f(n)은 다음과 같이 구성됩니다: f(n) = g(n) + h(n)
n은 각 상태 노드를 의미합니다. g(n)은 초기 노드로부터 노드 n 까지 도달하는데에 사용된 비용을 의미합니다. h(n)은 휴리스틱 함수로, 노드 n에서부터 목표 노드까지 도달하는데에 필요한 비용을 추정한 값입니다. 결과적으로 f(n)은, n 까지 도달하는데에 든 비용과 목표 상태에 도달할 때까지 들 비용에 대한 추정치의 합으로, 해당 노드가 최적해에 얼마나 가까울지 평가하는 기준이 될 수 있습니다.
8-퍼즐 문제에서 각 상태 노드에 대한 f(n)은 어떻게 구성되어야 할까요? 한 가지 분명한 점은 g(n)은 해당 노드까지 오기까지의 이동 횟수가 될 것이라는 점입니다. 그렇다면 h(n)은요? 어떻게 현재 상태에서 목표 상태까지 갈 때까지의 이동 횟수를 추정할 수 있을까요?
h1(n) : 불일치하는 타일 개수로 추정
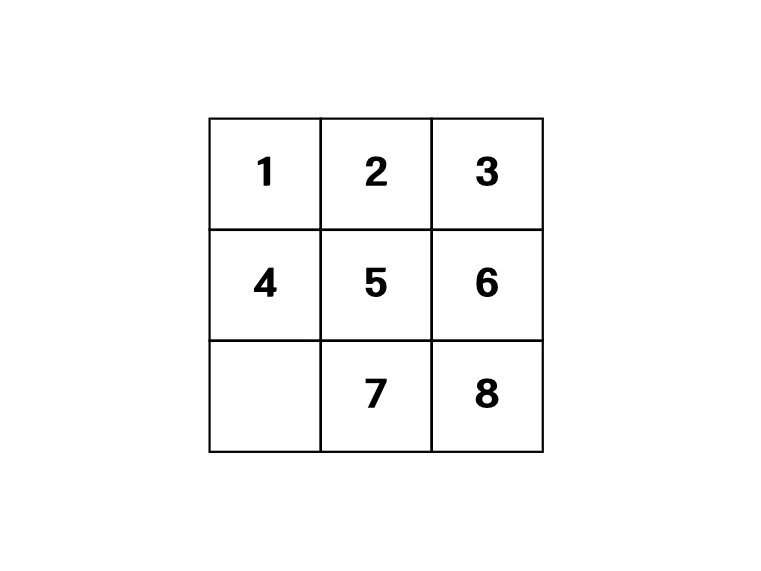
위 퍼즐을 봅시다. 1부터 6까지의 타일은 제 위치에 있고, 7과 8만이 잘못 배치되어 있습니다. RIGHT -> RIGHT 두 번의 움직임이면 퍼즐은 해결됩니다.
불일치하는 타일의 개수는 앞으로 남은 최소 움직임 횟수의 추정치로 동작할 수도 있는데, 이는 '틀린 칸을 맞추려면 적어도 이 만큼은 움직여야 한다'라는 하한의 의미로 사용될 수 있기 때문입니다. h(n)을 틀린 타일 개수로 정의하여 문제를 해결한다면 다음과 같이 구현해 볼 수 있습니다.
public static class Node {
final int[][] board;
final int moved;
final int misplacedTiles;
final int estimation;
public Node(int[][] board, int moved) {
this.board = board;
this.moved = moved;
this.misplacedTiles = h();
this.estimation = this.moved + this.misplacedTiles;
}
private int h() {
int count = 0;
if (board[0][0] != 1) count++;
if (board[0][2] != 3) count++;
...
if (board[2][1] != 8) count++;
if (board[2][2] != 0) count++;
return count;
}
}노드가 생성되는 시점에 틀린 타일 개수가 계산되며, 이는 지금까지 이동한 횟수와 합산되어 노드의 추정 결과값이 됩니다. estimation 값이 낮은 노드일수록 더 적은 횟수로 문제를 해결할 수 있을 것이라 예측되는 노드입니다. 따라서 이들을 우선적으로 탐색할 수 있도록 우선순위 큐를 사용해야합니다.
PriorityQueue<Node> q = new PriorityQueue<>(Comparator.comparingInt(n -> n.estimation));
//나머지 코드는 동일이렇게 문제를 해결하는 경우 노드 방문 횟수는 125,226회가 되어 기존 18만 회에 비해 약 25% 줄어들었음을 확인할 수 있습니다. 이는 고정된 규칙에 따라 탐색하지 않고, 생성되는 상태들에 대한 기대값을 기반으로 탐색 순서를 결정하여 불필요한 방문을 줄였기 때문입니다.
h2(n): manhattan distances로 추정
예측 비용을 추정하는 방법을 더 고도화하여 Manhattan Distance를 사용해보도록 하겠습니다. Manhattan Distance는 두 지점의 유사도를 평가하는 방법 중 하나로, 이를 사용한다면 단순히 틀린 타일 개수를 넘어, 타일이 가야할 위치와 얼마나 차이가 나는지까지 평가에 포함됩니다.
private int h() {
int dist = 0;
for (int r = 0; r < 3; r++) {
for (int c = 0; c < 3; c++) {
int v = board[r][c];
if (v != 0) {
int tr = (v - 1) / 3, tc = (v - 1) % 3;
dist += Math.abs(r - tr) + Math.abs(c - tc);
}
}
}
return dist;
}H1 코드에서 오직 h()함수만 위와 같이 수정해주었습니다. 위와 같이 평가 함수를 변경한 이후, 오직 7,751회의 노드만을 방문하여 문제를 해결하였습니다. 초기 BFS에 비하여 약 5%의 탐색만 진행한 것입니다.
Admissible Heuristics과 Performance
목표 상태에 다다르기 위한 최소 이동 비용을 추정하는 두 함수를 알아보았습니다. 이 두 함수들은 모두 허용적 휴리스틱Admissible Heuristics이기에 최적해를 찾는 것을 보장합니다.
허용적 휴리스틱은 '항상 실제 비용의 하한lower bound을 제공하는 휴리스틱 함수'를 의미합니다. 여기서 실제 비용이란 노드 n에서 목표 상태까지의 실제 최적 비용을 의미합니다. 즉, 현 상태에서 목표까지 실제로 5회의 움직임을 필요로 한다면, 휴리스틱 추정치는 5회를 초과해서는 안된다는 것입니다.
만약 h(n)이 실제 비용보다도 더 큰 값을 내버린다면, 어떤 노드가 더 저렴할 수 있음에도 불구하고 평가 함수 값이 더 커져서 탐색의 대상에서 밀려날 수 있습니다. 결국 더 좋은 해를 놓치고, A*는 비최적해를 선택하게 됩니다.
그렇다고 해서 휴리스틱 함수를 무조건 지나치게 보수적으로 설정하는 것이 좋은 것도 아닙니다. 휴리스틱 값이 실제 비용과 차이가 크면, 탐색 과정에서 많은 불필요한 상태들을 살펴보게 되어 성능이 저하됩니다. 반대로 휴리스틱 함수가 매우 정밀해서 실제 비용을 정확히 예측할 수 있다면, 탐색은 불필요한 우회를 전혀 하지 않고 곧바로 최적 경로를 찾아낼 수 있습니다.
결국 좋은 휴리스틱 함수란 항상 실제 비용을 넘지 않으면서도, 가능한 실제 비용에 가깝게 예측하는 함수라고 할 수 있습니다.