Infrastructure
Looker Studio BI 구축 - Firestore -> BigQuery 연동
2025-05-25
개요
작은 스타트업의 백엔드 개발자는 주요 정보를 접근하고 해석할 수 있는 몇 안되는 구성원으로서, 데이터를 집계하고 공유하여 유의미한 결과를 창출하기 위한 책임을 가지고 있습니다. 하지만 데이터를 공유하는 일은 여러가지 어려운점이 있습니다.
데이터 저장 포맷은 사람이 보기 좋은 상태가 아닌 애플리케이션이 다루기 좋은 상태로 저장이 됩니다. 아무리 서비스를 잘 이해하고있더라도, 비개발자라면 DB를 직접 들여다보는 것은 어렵습니다. 따라서 데이터는 데이터 사용자에게 적합한 형태로 변환될 필요가 있습니다.
또한 데이터들은 누적되어 크기가 상당히 커집니다. 서비스가 성장함에 따라 매 시간 생성되는 데이터의 양은 더욱 더 커질 것이며, 방대한 데이터를 단순히 전체 조회하거나 특정 조건으로 필터링하는 작업은 많은 시간과 컴퓨팅 자원을 소모하게 될 것입니다. 이는 분석의 효율성을 저해하고 실시간 의사결정을 어렵게 만들 수 있습니다.
데이터 시각화 툴은 유연해야 합니다. 약간의 변경이 생길 때마다 개발자의 손길을 거쳐야 한다면, 피드백도 늦어지고 분석 활동의 피로도도 높아질 것입니다. 최종적인 데이터 사용자가 데이터를 확인하는 형태를 변경하기에 용이해야합니다.
지금까지는 비즈니스적으로 사용되어야할 정보들을 주 단위로 엑셀 파일로 만들어 공유해왔습니다. 엑셀 파일로 정제된 데이터는 데이터 사용자가 보기에는 편했지만, 정적 파일이기에 실시간 데이터 반영이 어렵고 시각화에 한계가 있었습니다. 이러한 문제를 해결하기 위해 Google이 제공하는 서비스인 Looker Studio를 사용하여 데이터를 시각화하여 비즈니스 문제를 해결하는데에 도움을 주도록 환경을 구성했습니다. 이번 글에서는 Firestore의 데이터를 BigQuery에 연동하는 과정에 대해 이야기하고자 합니다.
Looker Studio - Connectors
Looker Studio는 데이터를 활용하여 유용하고, 읽기 및 공유가 쉽고, 완벽하게 맞춤설정이 가능한 대시보드와 보고서를 만들 수 있는 무료 도구입니다.
Looker Studio는 다양한 데이터 소스와 연동할 수 있는 커넥터를 제공합니다.
구글 커넥터는 구글이 무료로 제공하는 데이터 소스 연동 모듈로, 약 20개의 커넥터가 존재합니다. Google Cloud Storage, Miscrosoft SQL 서버와 같이 동적으로 변경될 수 있는 데이터 소스도 있으며, CSV나 Microsoft Excel 처럼 정적 파일 역시 데이터 소스로 사용할 수 있습니다.
모든 데이터 소스에 대해 구글이 연동을 지원하는 것은 아닙니다. 일부 상용 DBMS들이나 플랫폼들에서 자신들의 데이터를 Looker Studio에서 사용할 수 있게 커넥터를 개발해놓은 곳들이 있습니다. 이들 커넥터는 Partners Connectors라고 불리며, 일반적으로 커넥터 개발사에 비용을 지불하고 서비스를 이용할 수 있습니다.
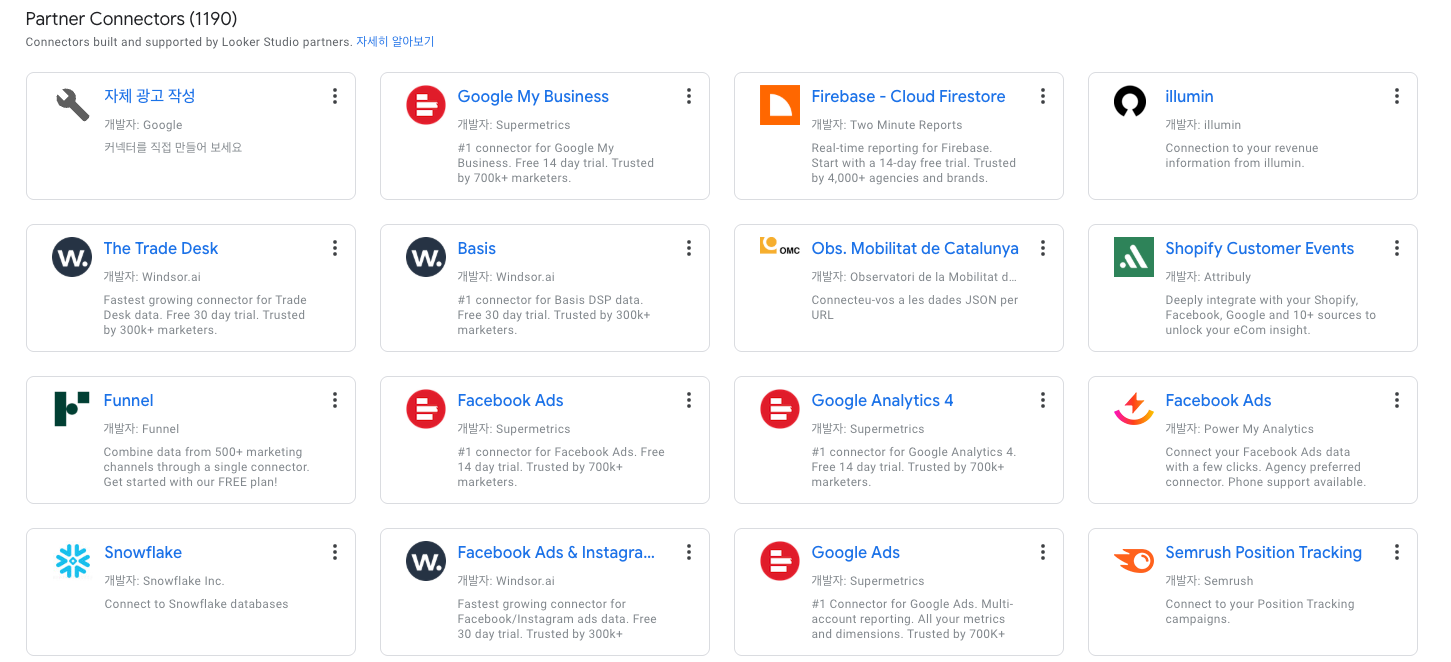
저는 Firestore의 데이터를 연동해야 했습니다. Cloud Firestore는 안타깝게도 구글 커넥터로 제공되지 않았고, 파트너 커넥터만이 존재했습니다. Cloud Firestore 파트너 커넥터의 개발사인 Two Minute Reports는 무료 플랜을 제공하지 않았기에, 서비스를 구독하던지 아니면 다른 방법을 찾아야 했습니다.
Looker Studio는 BigQuery 커넥터를 제공합니다. 따라서 Firestore의 데이터를 BigQuery와 연동하고, BigQuery와 Looker Studio를 연결하는 우회 방식을 택했습니다.
BigQuery 연동
BigQuery가 뭔가요
BigQuery는 Google Cloud가 제공하는 서버리스, 열 지향 기반의 데이터 웨어하우스로, OLAP 분석에 최적화되어 있습니다. 페타바이트급 데이터를 빠르게 분석할 수 있으며, 인프라 관리 없이 사용한 만큼만 과금됩니다.
Stream Firestore to BigQuery Extension
Looker Studio를 사용하기 위해 BigQuery의 저장소에 Firestore의 데이터를 저장해야합니다. Firebase는 Firestore의 데이터를 BigQuery에 실시간 연동해주는 익스텐션을 제공합니다.
Stream Firestore to BigQuery | Firebase Extensions Hub
위 링크로 들어가서 'Install in Firebase console'을 클릭하면 Firebase Project를 선택하는 창으로 이동됩니다. 원하는 Firestore 데이터가 있는 프로젝트를 클릭해줍니다.
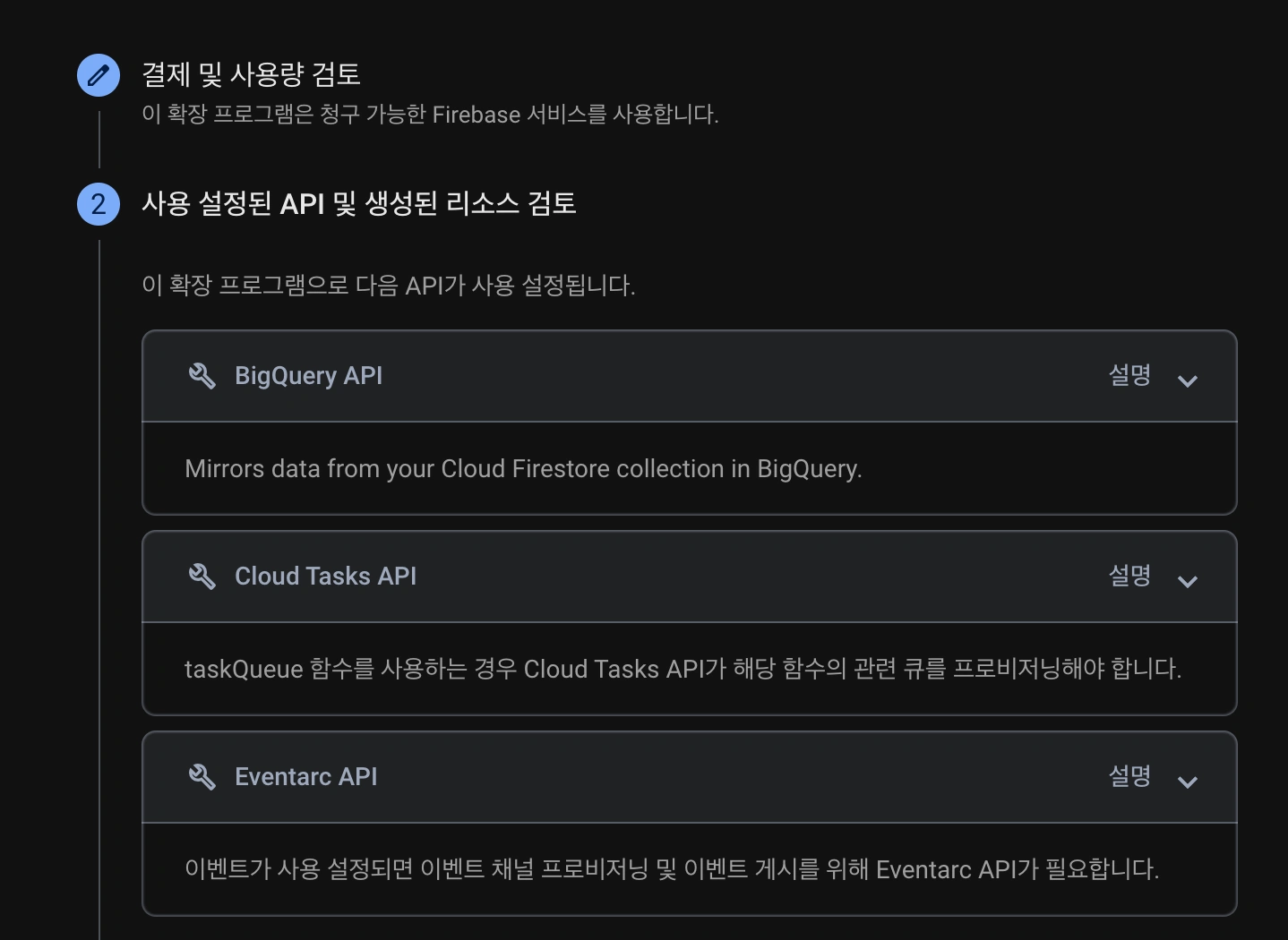
첫 단계는 결제 정보와 과금 안내에 대한 부분이며, 두번째와 세번째 단계는 이 익스텐션이 필요로하는 권한들에 대한 정보를 제공합니다. 익스텐션 사용과 함께 자동으로 권한이 부여되니 다음 버튼을 눌러 넘어가주면 됩니다.
네번째 단계는 구성 정보를 입력하는 단계입니다. 다음 요소를 신경써서 작성해줍니다.
1. Cloud Function Location, BigQuery Dataset Location
실시간 전송을 위해 사용될 함수와 BigQuery 데이터셋이 위치할 장소를 지정해줍니다.
2. BigQuery Project Id
BigQuery 측 프로젝트 ID를 기입해줍니다. 만약 프로젝트를 별도로 생성하지 않았다면 이곳에 입력하는 아이디로 BigQuery 프로젝트를 생성합니다. 기본 값으로 Firebase 프로젝트 ID가 작성되어있으니, 그대로 사용해도 무방합니다.
3. Firestore Instance ID, Firestore Instance Location
연동하고자 하는 Firestore의 인스턴스 식별자와 위치 정보를 기입해줍니다. Firestore console에서 확인할 수 있습니다.
4. Collection Path
연동하고자 할 컬렉션 대상의 경로를 입력해줍니다. 만약 Product 컬렉션을 연동하고 싶다면 Product만 입력해주면 됩니다.
5. Dataset ID
BigQuery에 생성될 데이터 셋이라는 단위의 식별자입니다. 기본값인 firestore_export로 두어도 무방합니다.
6. Table ID
BigQuery에 생성될 테이블의 prefix를 기입합니다. 컬렉션 명과 일치시키면 알아보기 편할 것입니다.
나머지 속성들도 확인해보시고, 다 완료가 되었다면 '확장 프로그램 설치'를 눌러줍니다.
약 5분 정도가 지나면 처리 완료 상태로 변경되며, 이후에는 Firestore 컬렉션의 이벤트들이 발생할 때 마다 BigQuery에 전달되어 테이블 구조로 저장될 것입니다. BigQuery 콘솔에 들어가면 다음과 같은 화면을 볼 수 있습니다.
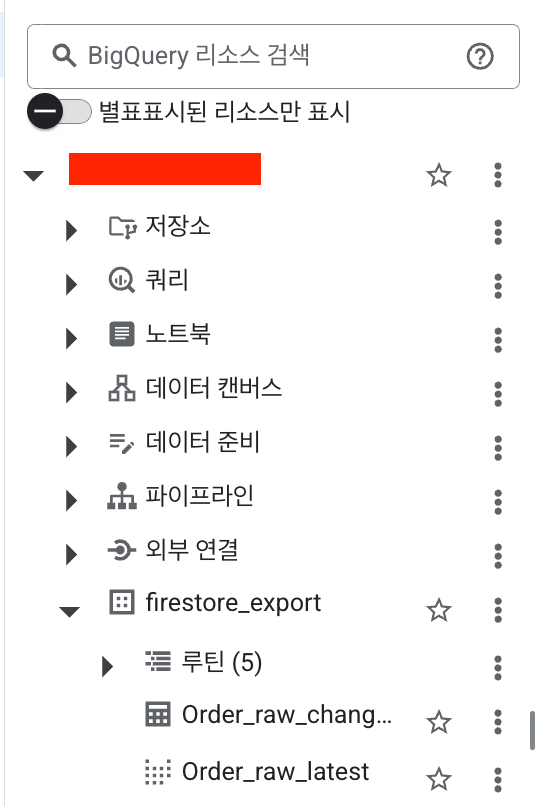
맨 아래 firestore_export가 익스텐션 사용으로 생성된 데이터셋입니다. 데이터셋 내부에 Table ID에 기입했던 이름이 접두사로 붙은 raw_changelog와 raw_latest 테이블을 확인할 수 있습니다.
raw_changelog 테이블은 문서의 모든 변경사항이 다 기록되어있는 테이블입니다. 1번 문서가 2번 수정되었다면, 해당 테이블에는 1번 문서에 대한 레코드가 2개가 생성됩니다. raw_latest는 각 문서의 최신본만 담고 있는 논리적 뷰 입니다. 1번 문서가 2번 수정되었다 하더라도 해당 뷰의 1번 문서는 마지막 변경이 발생한 버전만이 존재합니다. 분석의 필요성에 따라 테이블을 선택해서 사용할 수 있습니다.
Backfill
지금 단계에서도 Looker Studio에 데이터 소스를 연동할 수는 있습니다. 하지만 아직 몇가지 해결해야할 문제들이 남아있습니다. 그 중 첫번째 문제는 익스텐션을 연동한 후의 이벤트만 BigQuery에 반영되기에 그 이전의 데이터들이 존재하지 않는다는 점입니다.
따라서 연동 이전에 갖고 있던 데이터를 BigQuery에 복사하는 과정이 필요합니다. 이 작업은 직접 BigQuery의 API를 사용해도 되지만, firebase 측에서 미리 만들어놓은 대화형 프로그램을 사용할 수도 있습니다. 관련 내용은 문서에 더욱 잘 나와있어 링크만 남깁니다.
스키마 뷰 생성
아직 해결해야할 문제가 하나 남아있습니다. BigQuery에 들어가 데이터 테이블을 확인한다면 다음과 같은 스키마로 구성되어있음을 알 수 있습니다.
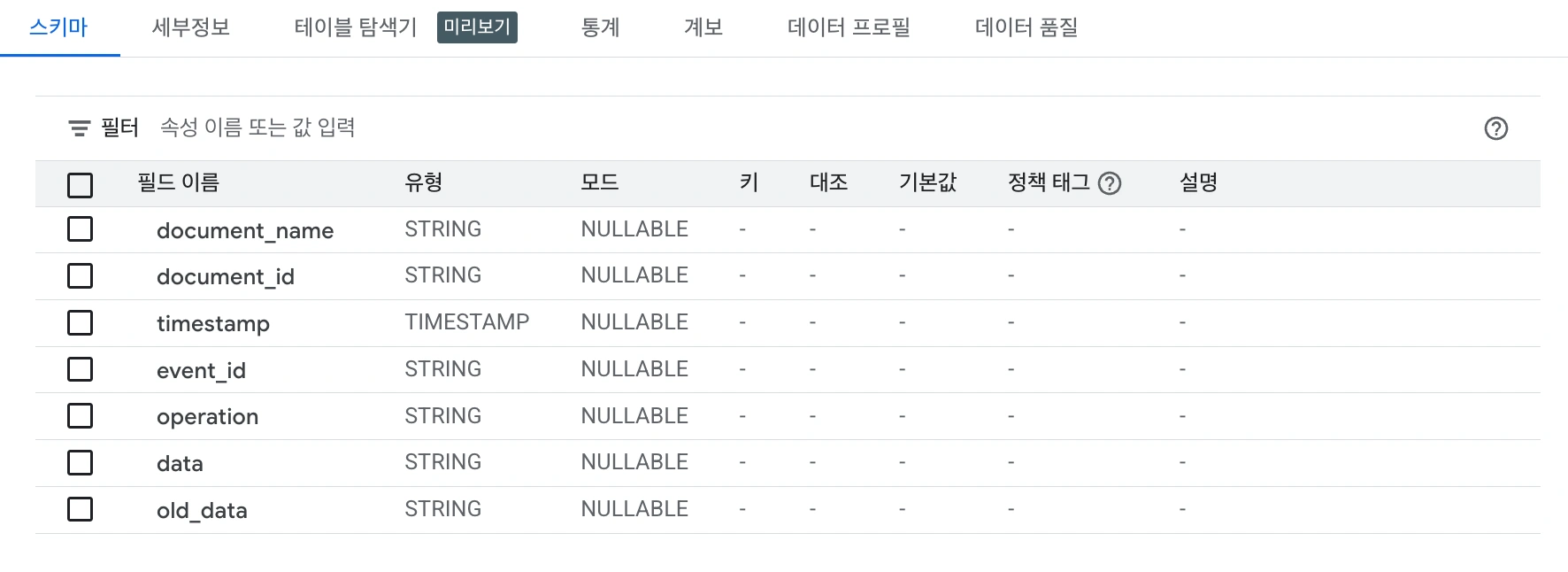
document_name, documetn_id, timestamp, event_id, operation 등은 문서에 대한 메타데이터입니다. 문서의 데이터를 담고 있는 필드는 data, 그리고 old_data입니다. 이들은 문자열 타입으로 되어있으며, 이들 값을 출력해보면 문서의 데이터가 JSON 형태의 문자열로 저장되어있음을 확인할 수 있습니다.
이는 행과 열로 이루어진 테이블 구조를 갖는 BigQuery와 JSON 구조를 갖는 Firestore의 형식 불일치 때문입니다. 이렇게 저장된 BigQuery의 테이블에 문서의 특정 필드에 대한 값을 필터링해서 보려면 다음과 같이 JSON 표현식을 통해 쿼리를 작성해야합니다.
SELECT JSON_VALUE(data, '$.price')
FROM `myproject.firestore_export.Order`
WHERE JSON_VALUE(data, '$.userId') = 'abc';이는 매 질의마다 문자열 파싱을 수행해야해서 성능적으로도 좋지 않고, 쿼리 캐시가 적용되지 않으며, 가져온 값들의 타입 정보도 없기에 후속 처리에도 불리합니다.
테이블에 대한 스키마 뷰를 만들어 이러한 문제를 해결할 수 있습니다. data 필드에 있는 JSON 값은 기본적으로 중첩된(nested) 구조이므로, 이를 RDB 테이블로 취급하기 위해 평탄화(flatten)하는 작업을 수행해야 합니다.
fs-bq-schema-views는 스키마 뷰 생성을 도와주는 익스텐션입니다. 위에서 수행한 백필 작업과 동일하게 대화형 콘솔로 작업을 수행합니다. 프로그램은 두 가지 방식으로 실행할 수 있습니다.
1. Gemini API가 스키마 뷰를 만들게 하기 (권장)
스크립트 실행 도중 Gemini API를 통해 스키마 뷰를 만들 것이냐고 물어보는 단계가 있습니다. 여기서 Y를 입력하면 스크립트는 Gemini API Key를 입력받으며, BigQuery의 데이터 셋 중 100개를 샘플링하여 적합한 스키마를 자동으로 생성해줍니다.
2. 스키마 뷰 직접 만들기
Gemini API를 사용할 것이냐고 물어보는 단계에서 N을 입력하면, 적용할 스키마가 있는 파일 경로를 입력받습니다. 원하는 경로에 아래와 같이 스키마가 정의된 파일을 미리 만들어놓고, 해당 경로를 입력해주면 파일을 읽어 스키마 뷰를 생성해줍니다.
{
"fields": [
{
"name": "name",
"type": "string"
},
{
"name": "age",
"type": "number"
}
]
}제 경우에는 두 방법이 다 먹히지 않았습니다. JSON 구조가 애플리케이션을 운영하는 과정에서 굉장히 많이 바뀌어서 일반화된 스키마를 만들 수 없었기 때문입니다. 이 때문에 매번 생성과정에서 타입에러가 발생했습니다.
저는 따라서 위 프로그램을 사용하지 않고 BigQuery 콘솔에서 직접 스키마 뷰를 생성했습니다. 단순한 필드는 '$.category'와 같이 JSON 표현식으로 바로 가져왔고, 중첩 구조가 있는 필드들은 하나의 필드로 관리하기 위해 중첩 select 문을 사용하여 하나의 문자열로 만들었습니다. 또한 시계열 분석을 수행하기 위해 epoch time으로 저장된 시간 관련 필드들을 시간 타입으로 변경해주었습니다.
SELECT
document_id AS recordId,
TIMESTAMP_MILLIS(SAFE_CAST(JSON_VALUE(data, '$.createdAt') AS INT64)) AS createdAt,
JSON_VALUE(data, '$.category') AS category,
(
SELECT
STRING_AGG(JSON_VALUE(option, '$.label'), ' | ' ORDER BY OFFSET)
FROM
UNNEST(JSON_QUERY_ARRAY(data, '$.options')) AS option WITH OFFSET
) AS optionSummary
FROM
`your_project.analytics_dataset.events_raw_latest`원하는 테이블에 우클릭 - 쿼리 작성을 눌러준 뒤, 스키마 뷰로 사용할 쿼리를 작성해준 뒤 '저장' - '뷰 저장'을 눌러줍니다.
어떠한 방법이든 스키마 뷰를 생성하면 아래와 같이 새로운 테이블이 생성됩니다.

이제는 새로 생성된 스키마 뷰를 사용하여 미리 구성된 테이블 구조로 쿼리문을 작성할 수 있으며, 파싱 성능 문제를 해결하고 직관적인 쿼리를 만들 수 있게 됩니다.
데이터 소스 준비 완료
Looker Studio에서 Firestore의 데이터를 사용하기 위한 모든 준비가 완료되었습니다.
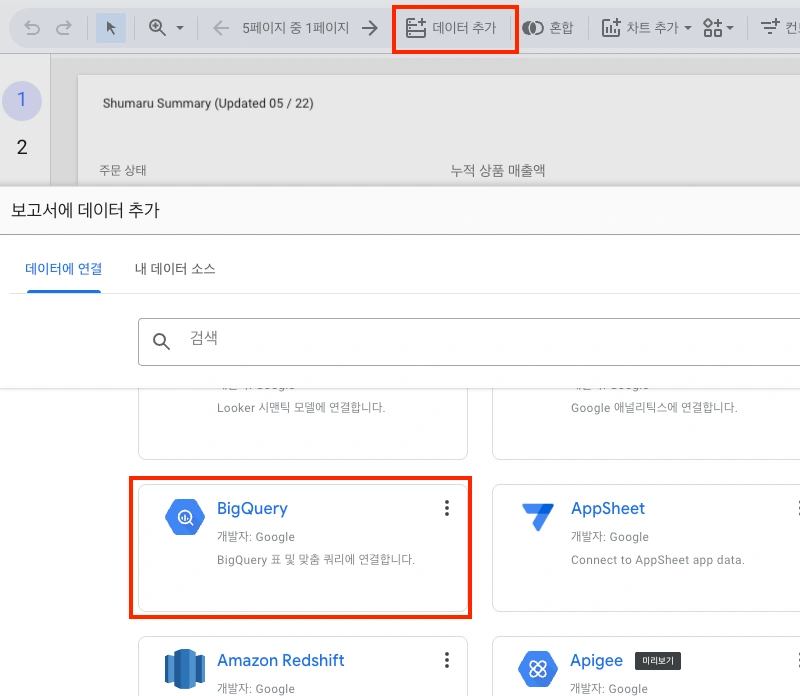
Looker Studio에서 새 프로젝트를 생성한 뒤 데이터 추가 -> BigQuery Data Connector를 눌러줍니다.
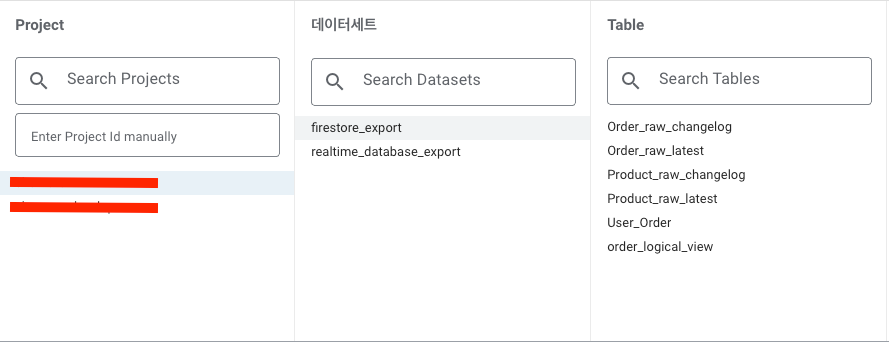
만들었던 논리적 뷰가 있는 프로젝트와 데이터세트를 선택하고, 원하는 테이블을 선택해줍니다. 이 데이터로 만드는 모든 그래프와 차트는 해당 테이블을 실시간으로 바라봅니다. 이를 통해 Firestore의 데이터를 데이터 분석 대시보드에서 실시간으로 확인 수 있는 환경이 구축되었습니다.
차트 제작 등 Looker Studio의 상세한 사용법에 대해서는 이 링크에 잘 정리되어 있으니 확인해보시면 좋을 것 같습니다.