Computer Science
IP 동작 원리와 단편화(Fragmentation) 알아보기
7/27/2025
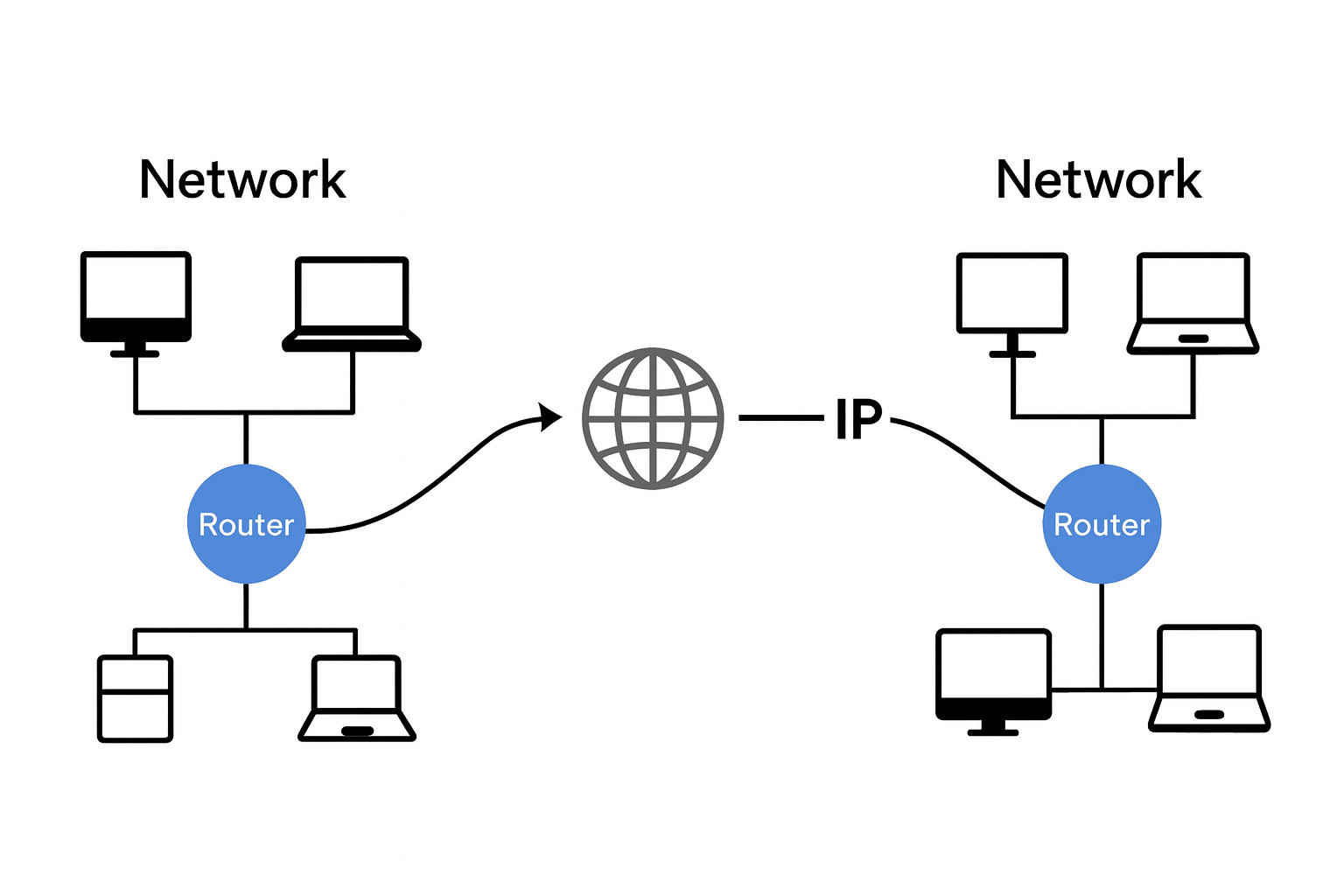
OSI 7 계층 중 네트워크 계층은 동일한 네트워크에 존재하는 호스트들 간의 데이터 전송 경로를 설정하고 전달을 수행하는 계층입니다. 현대 네트워크의 중추를 이루는 IP 프로토콜은 역할을 더욱 확장하여, 서로 다른 네트워크에 존재하는 호스트들 간의 데이터 전송inter-networking을 지원합니다.
Inter-networking 원리
네트워크란 호스트들과 그들 간의 연결의 집합입니다. 각 네트워크는 네트워크 관리자의 설계에 따라 호스트를 연결하는 방식과 사용되는 통신 프로토콜이 달라질 수 있습니다. 어떤 네트워크는 호스트들을 동축 케이블로 연결하고, 이더넷 프로토콜을 통해 통신하도록 구성할 수 있습니다. 반면, 또 다른 네트워크는 자체적으로 설계한 2계층 프로토콜을 사용하여 내부 통신을 수행할 수 있습니다. 이처럼 네트워크마다 구성 방식이 상이하기 때문에, 서로 다른 네트워크 간의 통신은 이루어질 수 없습니다.
IP는 위와 같은 문제를 해결하여 인터-네트워킹 서비스를 제공합니다. IP의 동작 원리는 아래와 같습니다.
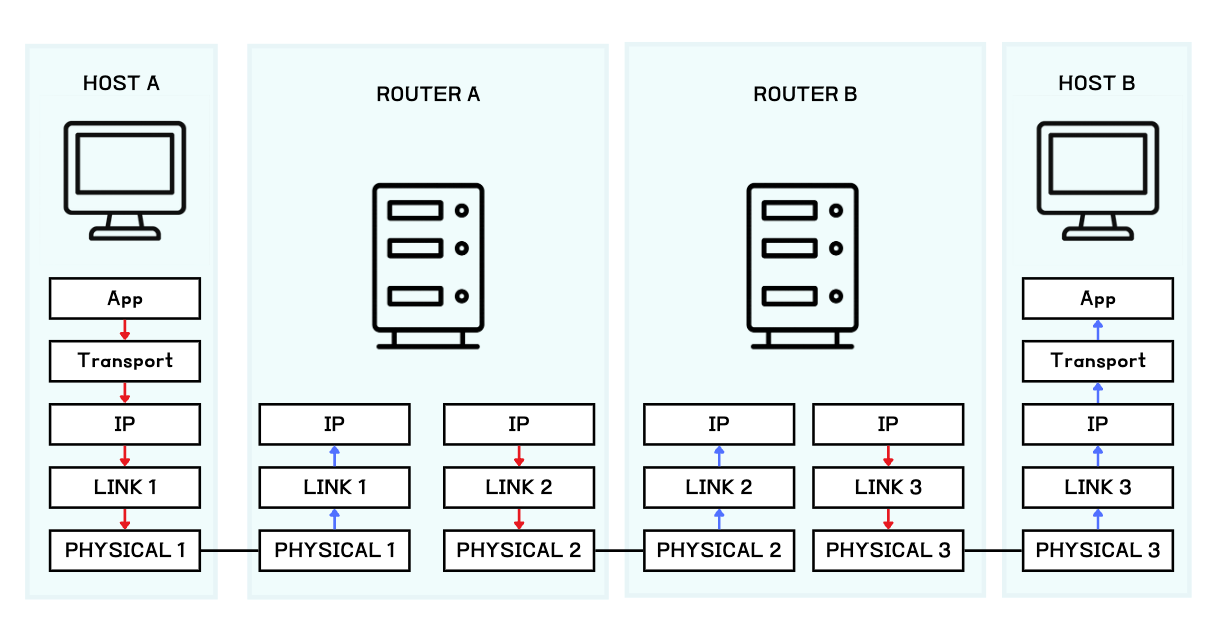
호스트 A는 호스트 B에게 메시지를 송신하고자 합니다. 보내고자 하는 데이터는 애플리케이션 계층과 트랜스포트 계층을 내려오며 캡슐화되고, IP 계층에 도착합니다.
IP 계층의 헤더에는 수신자인 호스트 B의 IP 주소를 담아서, 이 패킷이 전달될 목적지를 지정해줍니다. IP 헤더로 다시 한번 캡슐화된 데이터는 해당 네트워크의 링크 계층을 거치며, 다른 네트워크로 패킷을 전송해줄 수 있는 라우터로 전송됩니다.
라우터 A는 호스트 A가 속해있는 네트워크의 경계에 있어, 다른 네트워크로 패킷을 송신할 수 있습니다. 라우터 A는 IP 헤더를 해석하여 목적지 IP 주소를 확인하고, 목적지로 보낼 수 있는 경로를 결정한 뒤 해당 경로로 패킷을 전송합니다. 위 예시에서는 라우터 B로 전송하기로 결정되었습니다. 이 때, 전달받은 IP 패킷의 페이로드는 라우터 B가 속해있는 네트워크 프로토콜 스택에 맞게 새롭게 캡슐화됩니다.
라우터 B는 같은 원리를 통해 패킷을 수신한 뒤, 다음 경로를 결정합니다. 라우터 B는 결국 목적지인 호스트 B에 패킷을 전송합니다. 패킷을 수신한 호스트 B는 패킷을 디캡슐화하며, IP 계층에서 해당 패킷의 목적지 주소가 본인임을 확인합니다. IP는 상위 계층인 트랜스포트 계층으로 페이로드를 전달하며 서로 다른 네트워크에 존재하는 호스트 간 메시지 송수신이라는 목표를 완수합니다.
라우터는 서로 다른 네트워크로 데이터를 전송할 수 있는 인터페이스들을 가지고 있습니다. 이 덕분에, 네트워크 간에 사용하는 물리적 기술이나 링크 계층 프로토콜이 다르더라도, 각 구간에 맞는 방식으로 패킷을 변환하여 전달할 수 있습니다. 이렇게 함으로써, 이기종 네트워크 환경heterogeneous network에서도 통신이 가능해지는 것이 바로 IP 프로토콜의 핵심 역할입니다.
MTU 문제
위 동작에서는 한 가지 문제점이 있습니다.
MTU는 Maximum Transmission Unit의 약자로, 네트워크에서 하나의 메시지에 보낼 수 있는 최대 크기를 말합니다. 만약 링크 1의 MTU와 링크 2의 MTU가 다르다면 어떻게 될까요?
링크 1의 MTU가 1500 바이트이고, 링크 2의 MTU가 1000 바이트, 링크 3의 MTU가 500 바이트라고 가정해봅시다. 이 경우 호스트 A가 500 바이트 (상위 계층의 헤더 길이를 포함하여) 이하의 길이를 갖는 패킷을 전송한다면 아무 문제 없이 호스트 B에 도착할 것입니다. 하지만 호스트 A가 1500 바이트의 패킷을 전송할 때, 이는 호스트 A의 네트워크에서는 문제가 없는 크기지만 다른 네트워크에서는 지원하지 않는 크기이므로 일반적인 방법으로는 전송할 수 없게 됩니다.
단편화(Fragmentation)
IP 계층은 네트워크 간 서로 다른 MTU로 인해 발생하는 문제를 패킷을 네트워크가 지원하는 크기에 맞게 나누어 전송하고 이를 다시 모으는 방식으로 해결합니다. 이러한 방식을 단편화fragmentation와 재조립Reassembly고 합니다.
언제 단편화를 하는가
IPv4에서 단편화는 단편화가 필요한 순간에 수행합니다. IP 프로토콜에서 송신자가 패킷을 보낼 때 어떤 경로를 따라 패킷이 전송될 지 미리 알 수 없습니다. 따라서 경로상에 MTU가 더 작은 네트워크가 있을지도 알 수 없습니다. 따라서 일단 보내고, 만약 패킷 전송 시 해당 네트워크의 MTU보다 패킷 크기가 크다면 그제서야 패킷을 분할합니다.
분할된 단편은 독립적인 데이터그램
이렇게 분할된 패킷들은 독립적인 패킷으로 취급됩니다. 이를 통해 IP 프로토콜은 통일되고 일관된 구조로 패킷을 처리할 수 있게 됩니다. 이들은 같은 경로를 경유하지 않을 수도 있으므로, 만약 문제가 되는 네트워크를 지나 MTU가 충분히 큰 네트워크를 지날 때에도 분할된 단편들은 재조립되기 어렵습니다. 단편들의 재조립은 항상 목적지에서 수행됩니다.
단편화 헤더
IP는 단편화를 지원하기 위한 몇가지 헤더를 유지해야합니다.
1. Identification
Identification은 16비트 필드로, 목적지에서 재조립 시 각각의 단편들이 어떤 패킷으로부터 잘려나왔는지 식별할 수 있게 해줍니다. 주로 운영체제에서 유지하는 카운터 값으로 기본값이 지정되며, 단편화가 수행될 때 각각의 단편들은 동일한 Identification 값을 갖습니다.
2. Offset
Offset은 13비트 필드로, 각 단편이 원래 IP 패킷의 페이로드 중 어디에 해당하는지를 나타냅니다. 단위는 8 바이트이며, 따라서 Offset 값이 180이라면 해당 단편은 원본 페이로드의 1,440번째 바이트(=180 × 8)부터 시작하는 데이터를 담고 있는 것입니다.
3. Flags
단편화와 관련된 두 개의 비트가 있습니다.
DF-bit은 Don't Fragment의 약자이며, 이 비트가 1로 설정되어 있으면 해당 패킷은 절대 단편화되지 않아야함을 의미합니다. 송신자 측에서 설정하며, MTU 문제로 인해 단편화가 필요한 경우 해당 패킷은 단편화를 수행하지 않고 폐기합니다.
MF-bit은 More Fragments의 약자로, 해당 패킷 이후에도 더 많은 단편이 존재함을 의미합니다. 패킷이 5개로 쪼개졌다면, 4번째 패킷까지는 MF-bit이 1로 설정되어 이후 패킷이 존재함을 알리고, 5번째 패킷은 0으로 설정되어 더 이상의 패킷이 존재하지 않음을 표현합니다.
단편화 예시
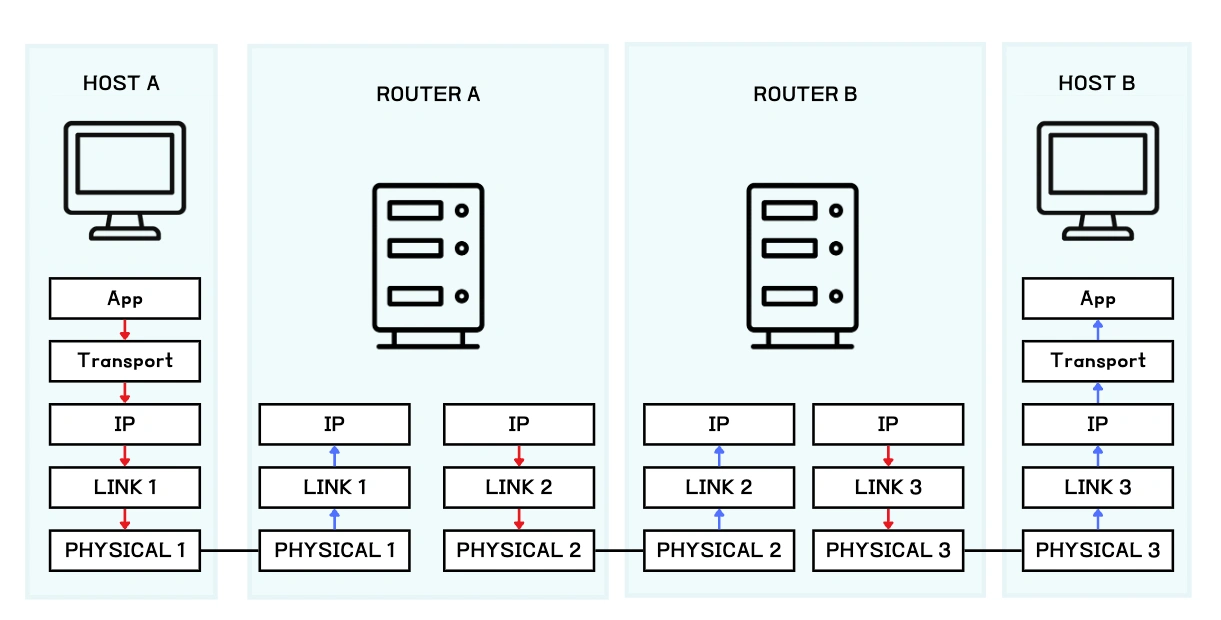
위 그림에서 호스트 A가 호스트 B에 1460 바이트의 페이로드를 갖는 IP 데이터그램을 전송한다고 가정합니다. L1, L2, L3 링크는 모두 20 바이트를 헤더로 가지며, 각각의 MTU는 1500, 1000, 500 바이트 입니다.

호스트 A에서 1460 바이트를 페이로드로 갖는 IP 데이터그램을 전송합니다. L1 프로토콜의 헤더는 20 바이트이니 링크를 통해 전송될 데이터는 총 1500 바이트입니다. 이는 L1 프로토콜의 MTU와 같으므로 문제 없이 라우터 A로 전송될 수 있습니다.
라우터 A에서는 1480 바이트의 IP 데이터그램과 20 바이트의 L2 헤더를 포함한 1500 바이트의 패킷을 전송하려고 시도하나, 이는 L2의 MTU인 1000 바이트를 넘기므로 전송할 수 없습니다. 따라서 이 패킷은 단편화되어야 합니다.
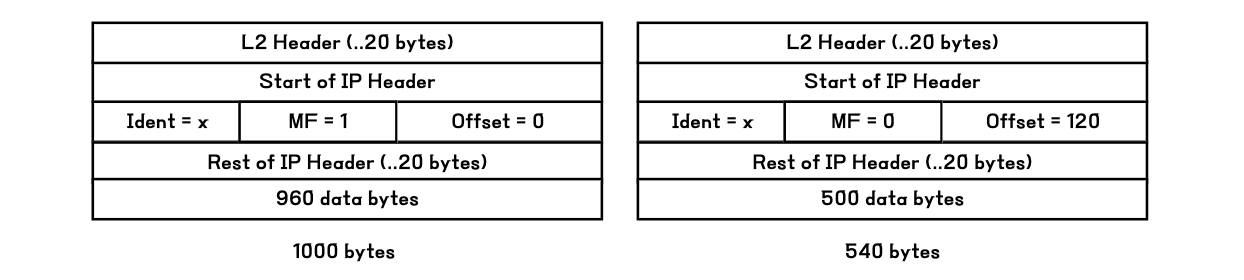
단편화된 두 패킷 모두 동일한 Identification을 물려받습니다. 이는 추후 목적지에서 재조립할 때의 기준이 됩니다.
첫 번째 패킷은 1460 바이트의 원본 IP 페이로드 중 첫 960 바이트만을 담습니다. 첫번째 바이트부터의 데이터를 담고 있으므로 Offset은 0으로 설정됩니다. 해당 패킷 이후의 단편이 남아있으므로 MF 비트는 1로 설정됩니다. 이후 IP 헤더와 L2 헤더가 합쳐져 1000 바이트 패킷이 되며, 이는 L2 링크를 통해 전송될 수 있습니다.
두 번째 패킷은 1460 바이트의 원본 IP 페이로드 중 남은 500 바이트를 담습니다. 960번째 바이트부터의 데이터를 담고 있으므로 Offset은 120 (= 960 / 8)으로 설정됩니다. MF 비트는 0으로 설정되며, 이는 더 이상의 단편이 존재하지 않음을 의미합니다. IP 헤더와 L2 헤더가 붙은 패킷은 540 바이트로 L2 링크를 통해 전송될 수 있습니다.
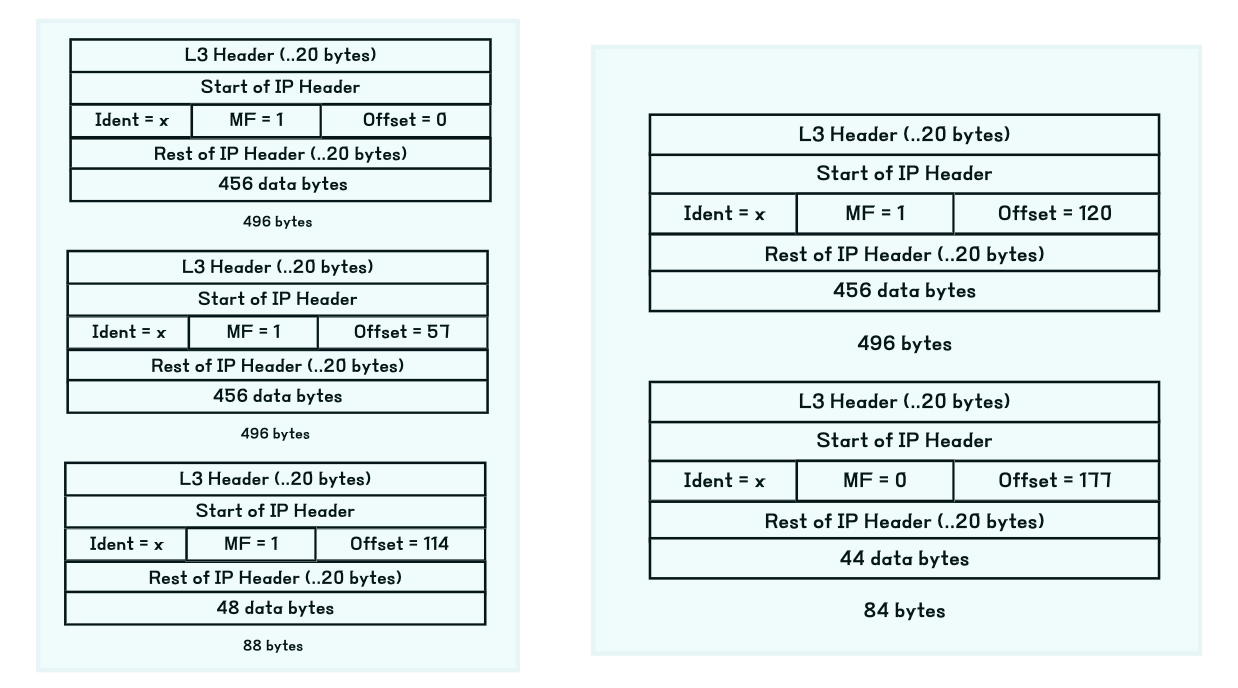
단편화된 패킷은 재단편화될 수 있습니다. L3 프로토콜의 MTU는 500이므로, 각각 1000, 540 바이트를 갖던 패킷들은 역시 단편화되어야 합니다.
이 때 좌측 패킷 중 일부는 MTU인 500 바이트를 꽉 채우지 않고 456 바이트만 전송한 것을 볼 수 있습니다. IP 헤더의 Offset 필드는 8바이트 단위로 오프셋을 표현하므로, 단편의 페이로드 길이는 8의 배수여야만 Offset으로 정확히 기술할 수 있습니다. 따라서 MTU를 넘지 않는 선에서 8바이트 단위로 표현 가능한 가장 큰 수인 456 바이트만을 전송합니다.
재단편화 동작까지 본다면 MF 비트의 설정은 다음과 같은 규칙을 따른다는 것을 알 수 있습니다. -- "만약 원본 패킷의 MF가 1이라면, 단편 역시 1을 가져야 한다. 만약 0이라면, 단편 중 마지막 단편을 0으로, 나머지는 1로 설정한다."
이렇게 전송된 단편들은 목적지에서 Offset을 기준으로 페이로드를 조합합니다. 이를 통해 최종적으로 송신지에서 보내고자 했던 1460 바이트(456 + 456 + 48 + 456 + 44)를 얻을 수 있습니다.
IPv6에서는 없어진 라우터에서의 단편화
IPv4는 라우터에서의 단편화를 허용하지만, 오늘날 대부분의 네트워크에서는 이를 회피하는 설계가 일반적입니다. 더 나아가 IPv6에서는 공식적으로 기능이 제거되었습니다. 이는 단편화 작업이 성능 오버헤드를 초래하기 때문입니다.
패킷을 단편화하는 작업은 라우터에 추가적인 CPU 연산과 메모리 복사 작업을 발생시킵니다. 특히 고속 네트워크 환경에서는 라우터가 패킷을 최대한 빠르게 전달하는 것이 중요한데, 단편화는 이러한 하드웨어 기반 포워딩 성능에 부담을 주는 병목 요인이 됩니다.
IPv6는 이러한 비효율을 제거하고자, 모든 단편화 작업을 송신자만 수행하도록 설계하였습니다. 경로에 따라 허용되는 MTU를 송신자가 미리 파악하여, 처음부터 적절한 크기의 패킷을 전송하도록 유도합니다. 이를 통해 라우터는 빠르고 단순하게 패킷을 전달하는 역할에 집중할 수 있게 되었으며, 고성능 네트워크의 병목 요소를 줄이는 데 기여합니다.